Integrating MES and ERP Systems Through a Unified Namespace
So far, we’ve discussed Unified Namespace integrations with MQTT and Sparkplug B, Ignition which have mostly focused on process data from instruments, equipment, and PLCs. While this is very valuable, it isn’t the whole story of a Unified Namepace, since process data will eventually make its way into the various other systems used to run manufacturing plants.
In this post, we will discuss the basics of implementing an ERP to MES integration using a Unified Namespace to demonstrate integrating non-process specific data between systems.
We believe that for real-time data, the Unified Namespace approach can provide concrete advantages over a traditional integration approach. Later in this post, we will also explain our opinions in detail about handling historical data. Generally, real-time and historical data processing are two different problems that only seem like two sides of the same coin. So, while Unified Namespaces work great for real-time data, they also have severe limitations when working with historical data.
Important Note:
We will outline the process in detail, however if you are familiar with the non-Unified Namespace approaches: using an API call to get data from the ERP system, running a query against the database directly, or potentially reading in a file with the latest data, please note we are moving from those "pull" models to a "push" model.
This post also glosses over how the data gets out of the ERP system and into the Unified Namespace using MQTT. The specifics of that process are dependent on a number of factors and will be case-by-case for your particular project.
Instead of the MES system requesting or pulling data from the ERP system when it needs information, the ERP system will be pushing data to the Unified Namespace as it changes. While the end result will be similar, the MES system will need to account for data potentially changing at any time so we will need to build in buffers around data interactions to avoid unexpected behavior. For example: if the production schedule changes in the middle of a run, and the current active run's data is no longer in the schedule because the ERP data is for the next day. Or if a product code we are actively working with in the MES system is removed from the ERP system without warning. Normally, we would account for these types of scenarios in the code that’s requesting data from the ERP system—the major difference is that in the old way of doing things we would normally be in control of when that happens.
We will cover these concepts in more detail in the discussion of historical data management later in this post.
MES and ERP Integrations 101
First, let’s cover what we will integrate with these two systems.
The common components of all MES Systems are:
Product Codes and Work Orders (What are we making?)
Production Schedules (When are we making it?)
OEE (How is our production doing?)
Beyond those components, we have the option for additional integrations—including but not limited to:
Bills of Material
Recipe Management
Quality Control Management
Personnel Scheduling and Management
Track and Traceability
Statistical Process Control
Document Management
Maintenance Management
Inventory and Warehouse Management
Given the level of detail associated with the less common features, we will discuss them in future posts. In this post, we’ll focus on two of the common components in the first list. For more information on how to integrate process data with a production model which would directly apply to OEE integrations in a Unified Namespace, be sure to read our previous post.
We will be writing this post from the perspective of the MES domain. In most manufacturing organizations, the ERP system is the glue holding the entire business together to keep it operating smoothly. Also, it’s very common for IT and internal development teams to manage any and all access to and from the ERP system. We will assume they are sending us data via the Unified Namespace based on our previously agreed upon format and topic structures using MQTT. In this post, we will specify those topics and data structures, but we will leave out the process of getting data from the ERP system into the Unified Namespace. If that is something you really want to see we can dig deeper, just reach out and let us know you'd like more info!
What Are We Making?
Product Codes

Before we can build a production schedule for the plant floor, we need to know what we’re producing.
In an ERP system, this is commonly referred to as a Product Code, though it could also be a Stock Keeping Unit (SKU), or it may have a company-specific name. Regardless of the term used to describe it, a Product Code record in an ERP system usually consists of a part number, a description, and some meta data including things like unit of measure, price, and whether it is a finished good or an in-process product for use in the manufacturing process.
Sometimes meta data is encoded in the product number itself, and sometimes it is included as additional columns in the ERP system's database.
For this example, we are using a paint manufacturing facility where they can make various colors and types of paint in either 32oz, 64oz, or 128oz cans.
The product product code format is described in the image above. P for "Paint" followed by a letter indicating the type of paint:
A - Acrylic
L - Latex
O - Oil-based
P - Polyurethane
The first set of numbers indicates the color and type of paint based on an encoded value, and the second set of numbers indicates the size of the can this product code uses. From the information in the product code, we can quickly determine the exact product we are making. If we need to add more product codes in the future, we have a defined format. Adding new codes will be easy and everyone will understand them.
Using product codes on the manufacturing side of the business also allows us to easily integrate with recipe management systems when we want to add them to our process control architecture.
Work Orders

In addition to our product codes to tell us what to make, work orders will tell us how much we need to make and how it will be packaged.
Typically, work orders are based on customer orders to give us an overall quantity of what we need to make. The work orders are then filtered through our production scheduling system to tell us when to produce what’s on the work orders.
If the schedule is created manually, our production scheduling algorithms may simply be in someone's head. Or, we might be able to create a set of rules based on past production data. We can use guidance from process engineers to further refine our schedules before they hit the plant floor.
In our example, the work orders will define a work order number and include the product code, how many total ounces of paint we will make, and how many of each size can we will use for the finished product. In large scale production facilities (or if we are making a large quantity of parts for many small orders) we might make enough product to fulfill many work orders in a particular production run.
When necessary, we might also create work orders for cleaning, changeover, or maintenance processes if they aren't part of our overall production schedule. We can even create work orders for commissioning runs if we want to track information on new equipment once it is ready to run product.

When Are We Making It?
Production Schedule Integration
The final piece of data we for our basic ERP and MES integration is the production schedule. The production schedule takes into account our work orders and product codes, tells us what and how much to make, and when we are going to make it.
The schedule can be as detailed as necessary. We will keep this example relatively simple and consider three pieces of equipment: a mixing tank, a storage tank, and a canning line. Once paint is mixed in the mixing tank, it is sent to a storage tank, and when it’s ready we can send it to the canning line to be packaged.
A more complicated example would include the can labeling line. In our example, we’ve assumed we have all the labeled cans we need. Also, note that we are not accounting for raw ingredient availability, storage location, or any shipping or receiving concerns.
How Do We Use This Data?
Now that we have defined all of our data, here’s how we’ll use it in the MES system once it is inside of our Unified Namespace.
Let's start with the raw data. In this case, the Unified Namespace receives JSON objects from the ERP to represent our product codes, work orders for a given period of time, and our production schedule for a period of time. These will be the "current state" or real-time data we will use to run the manufacturing operation. Once we go through the real-time state, we will discuss an approach for historical data integration.
Product Codes
We will first start with product codes. To avoid a lot of complexity when integrating an ERP system in an Industry 3.0 way, we will have the ERP system push data to the Unified Namespace for us. Yes, most ERP systems don't support MQTT directly. This will likely require some additional technology to convert it into the right format. Please reach out if you have questions about options for converting the data.
For our simple example, we will pass the data along as a JSON object. Below is an example of a product code entry. The rest will have the same format, but with different specific data for each entry:
{
"product_code": "P-A-19-032",
"description": "White Acrylic Gloss 32oz",
"paint_type": "Acrylic",
"finish": "Gloss",
"size": "32 oz",
"brand": "Color Splash"
}
Here we have the product code, description, other relevant metadata. Using this data, we could populate a list of every active product code. For example, we could set up a dropdown for the current product codes in the system.
When our MES system sees the product code topic change, we can read in the new data and write out the scripts we need to access the data however we wish.
Once we have all the relevant data we need, we will run through an example of how we will use this data in the system to build the production schedule.
Work Orders
Next, we will look at the Work Order data sent to the Unified Namespace from the ERP system. Here is an example of a work order:
{
"work_order_id": "WO-1005",
"product_code": "P-A-39-032",
"total_ounces": 41678,
"can_sizes": {
"128_oz": 225,
"64_oz": 112,
"32_oz": 60
}
}
We have a work order ID, product code, total batch size and count for each individual can we need to produce as part of this run.
Production Schedule
Finally, we have data for the production schedule:
{
"work_order_id": "WO-1001",
"product_code": "P-A-15-064",
"processes": [
{
"process_name": "Mixing",
"start_time": "5/7/2023 20:00",
"end_time": "5/7/2023 22:30"
},
{
"process_name": "Storage Tank",
"start_time": "5/8/2023 00:00",
"end_time": "5/8/2023 12:00"
},
{
"process_name": "Canning Line 128 oz",
"start_time": "5/8/2023 03:00",
"end_time": "5/8/2023 06:00"
},
{
"process_name": "Canning Line 64 oz",
"start_time": "5/8/2023 06:00",
"end_time": "5/8/2023 09:00"
},
{
"process_name": "Canning Line 32 oz",
"start_time": "5/8/2023 09:00",
"end_time": "5/9/2023 00:00"
}
]
}
The productions schedule data will give us the relevant work order and product code as well as the intended start and stop times for each line. I desired, we could also pass along the shift as a separate metric for additional information on the schedule, but we left it off for the time being.
Assemble the Schedule Using the Unified Namespace
Using the product code, work order, and production schedule information from the Unified Namespace, let's build out the production schedule for the line.
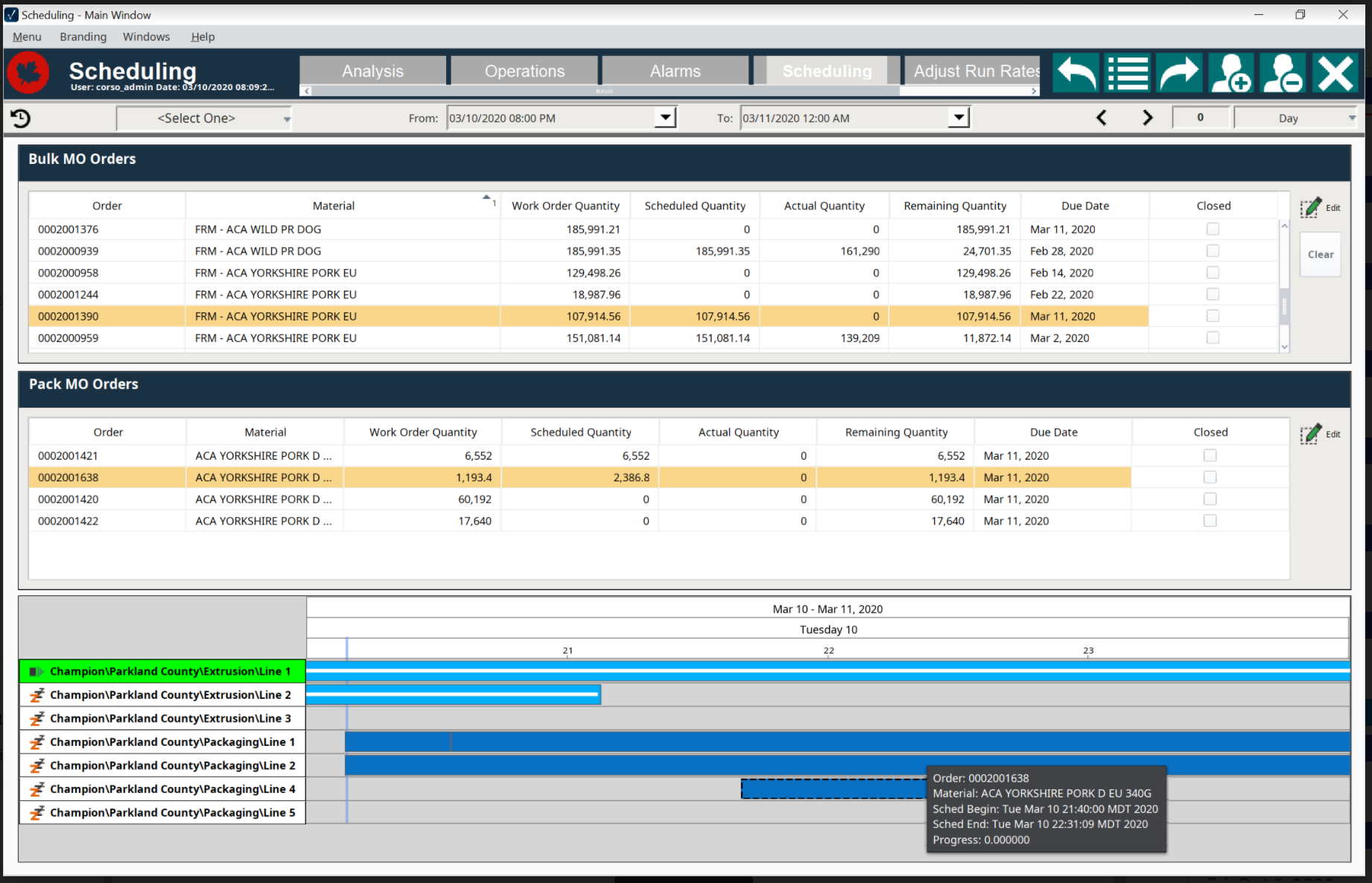
For this example, we will use the Equipment Schedule Component in Ignition’s Perspective module. The overall process of populating component is pretty straightforward based on the properties. We will explain the process and provide a graphic of the data mapping.
Here’s the basic process:

Whenever the product code list, the work order list, or the schedule are updated, we will grab them from the ERP system. Then, we’ll loop through the schedule entries and break out the start and end times for each process. We’ll map them to the Equipment Schedule Component’s scheduledEvents property with to the correct item id (where each item is a row in the schedule). We’ll parse the work order id value as well. For each work order, grab the product code, and look up the description from the product codes data. Populate the product description into the relevant property in the equipment schedule, and grab the quantities for each can size in this work order. For the canning line, we’d add entries for each can size on the schedule and assign them to the correct item id.
Once you have mapped all the data to the Equipment Schedule you are good to go. You will still need to manage items like the progress bar values and potentially extend the scheduled events in case of delays (as well as highlight the current run), however this is outside the scope of this post.

Looking Back at Past Data
Now, let’s assume that we’ve made a particular production run, tracked it all in the MES, and updated the ERP system. Now we need to understand the next part of the technology stack. At some point you will want to run a report on everything you produced during a particular period of time, perhaps even since the beginning of "time" with your system.
To make our lives infinitely easier, we’ll need to break out of the Unified Namespace concept. Yes, you can still use the Unified Namespace if you know exactly the report data you want to use, or if you are running daily reports and saving PDFs elsewhere. In our example, we will be focusing on the ad-hoc style of reporting.
When we are working with real-time data, we can use push methods to send the most up to date values to other systems from our particular domain. The ERP system will send the current schedule, the MES system will pull that in, and then integrate it with the process control system to run a work order. The MES and process control systems can push data back to the Unified Namespace to update all of the other systems on the run's current status.
A process historian will collect process data to save in a database, and when the run is completed we can update the ERP system from the MES system with the relevant information.
Correlating Historical Data
When we want to go back in time to run a report spanning multiple systems in the Unified Namespace, this push methodology can be very cumbersome. Although, you could have a trigger that the MES system sends to the Unified Namespace to alert other systems to push particular data for a report. This could even apply when trying to collect historical data for a trend. The other systems could update particular topics and then you could parse the data to build a report.
However, if multiple people are trying to view multiple reports at the same time, you would quickly run into an issue with the pushed data overwriting the topics before someone can pull a report.
This is when we realized that a Unified Namespace isn't a coin with real-time data on one side and historical data on the other. If you wanted to take the money analogy to its natural end, some folks would say that the Unified Namespace was the paper the money was printed on, but we digress…
Utilizing historical data can be much easier with the Industry 3.0 approaches of connecting systems. Your reporting engine can query the ERP system using a traditional method (a database connection or an API). It can query specific tags and time periods from the process historian, and get OEE information from the MES database. Then it can parse everything into the right format and generate a report.
Data Lakes
You might say "well why not simply send all of the data to a data lake?" And while we would agree that this is a feasible option, you still will not be able to directly use the Unified Namespace for historical data.You will still need to run a query against the Data Lake to get the data you need for the report—and it will be a pull method, not a push method.
Data lakes are a bigger topic than we will fit into this post. While they can provide an approximation to a Unified Namespace for storing your data, getting data out of them can be an entirely different animal than what you could solve with a Unified Namespace.
Wrapping Up
For real-time data, Unified Namespaces solve the problem of translating complex data between many different systems. This is accomplished by pre-planning the specifics of the Unified Namespace and enforcing them across the entire technology stack.
This solves many problems for situations like integrating MES and ERP systems. And, moving from a pull model to a push model solves a lot of problems you would face when integrating with ERP systems in general.
But, Unified Namespaces do not solve all problems—especially in the case of managing and accessing historical data. While some technology like Data Lakes exists to unify data storage, it does not solve the problem of access. When you are analyzing data, we believe you will have a much higher level view and understanding of what you need. So, using Industry 3.0 approaches is totally okay in those instances. Until you fully define your reporting needs, you will still likely need people to parse and format your data in a useful way. Trying to apply the wrong tool to the job will make everyone's lives harder.